
MySQL 的表是用什么方法来定位“一行数据”的?
如果你创建的表没有主键,或者把一个表的主键删掉了,那么 InnoDB 会自己生成一个长度为 6 字节的 rowid 来作为主键。
rowid 是每个引擎用来唯一标识数据行的信息。
对于有主键的 InnoDB 表来说,这个 rowid 就是主键 ID;
对于没有主键的 InnoDB 表来说,这个 rowid 就是由系统生成的;
MySQL如何进行随机排序
方案一(最慢,慎用)
select word from words order by rand() limit 3;
执行过程中需要临时表和排序,速度比较慢
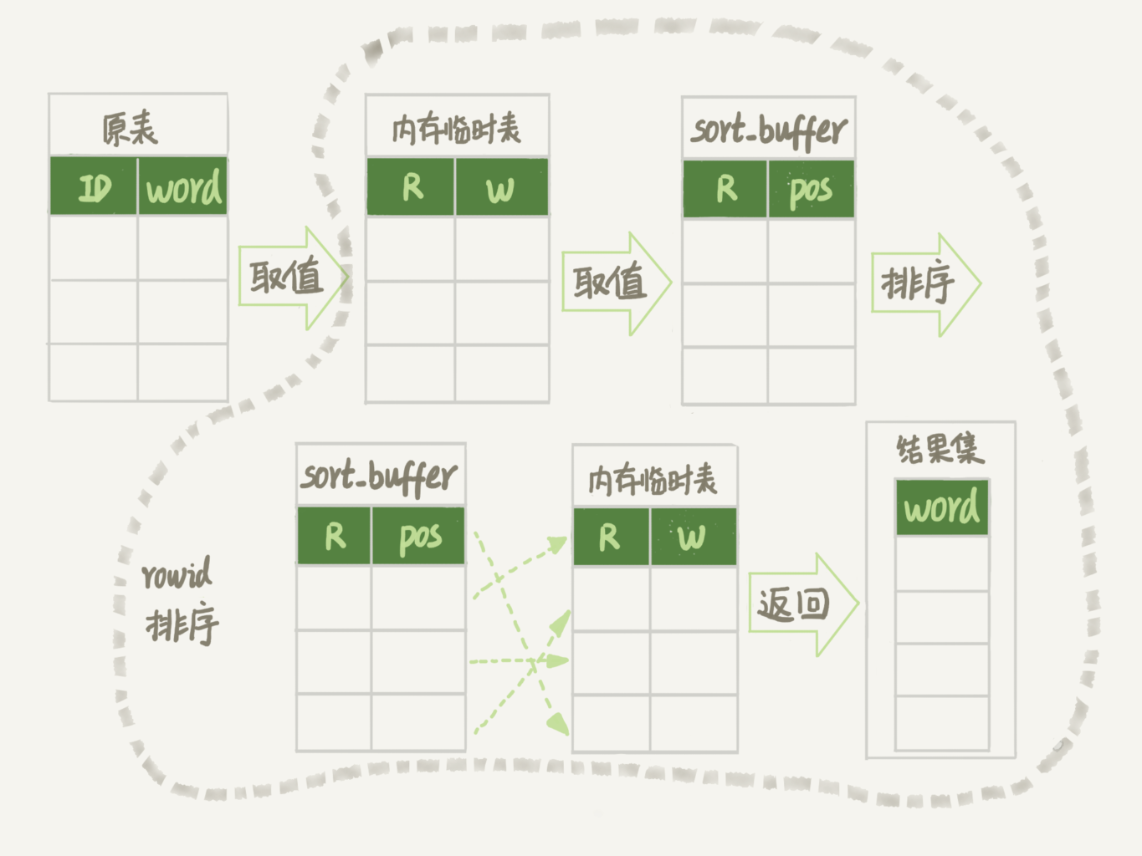
order by rand() 使用了内存临时表,内存临时表排序的时候使用了 rowid 排序方法。
如果临时表大小超过了 tmp_table_size,那么内存临时表就会转成磁盘临时表。
方案二
-
取得这个表的主键 id 的最大值 M 和最小值 N;
-
用随机函数生成一个最大值到最小值之间的数 X = (M-N)*rand() + N;
-
取不小于 X 的第一个 ID 的行。
select max(id),min(id) into @M,@N from t ;
set @X= floor((@M-@N+1)*rand() + @N);
select * from t where id >= @X limit 1;
优点:这个方法效率很高,因为取 max(id) 和 min(id) 都是不需要扫描索引的,而第三步的 select 也可以用索引快速定位,可以认为就只扫描了 3 行。
缺点:如果 ID 中间有空洞,那么选择不同行的概率就不一样,不是真正的随机。
优化方法:把空洞处理掉,比如:原来单词存在A表,新建B表 ,执行 insert into B(word) select word from A. B的id是自增的,就会生成连续的主键。
方案三
- 取得整个表的行数,并记为 C。
- 取得 Y = floor(C * rand())。 floor 函数在这里的作用,就是取整数部分。
- 再用 limit Y,1 取得一行。
如果要随机取多个值:
select count(*) into @C from t;
set @Y1 = floor(@C * rand());
set @Y2 = floor(@C * rand());
set @Y3 = floor(@C * rand());
select * from t limit @Y1,1; //在应用代码里面取Y1、Y2、Y3值,拼出SQL后执行
select * from t limit @Y2,1;
select * from t limit @Y3,1;
优化一下:
前提:Y1 < Y2 < Y3
id1 = select * from t limit @Y1,1;
id2= select * from t where id > id1 limit @Y2-@Y1,1;
select * from t where id > id2 limit @Y3 - @Y2,1;
扫描行数从Y1+Y2+Y3+3优化为Y3+3
建议
在实际应用的过程中,比较规范的用法就是:尽量将业务逻辑写在业务代码中,让数据库只做“读写数据”的事情。