
什么是Kafka
Kafka应用场景
一、消息系统
二、存储和持续处理大型数据流
三、实时流平台
Kafka 安装
- 安装Kakfa 的依赖应用ZooKeeper
ZooKeeper 是一个分布式应用程序协调服务。
sudo docker run -d --restart=unless-stopped --name zookeeper --network host zookeeper
- 安装Kafka
sudo docker run -d --restart=unless-stopped --name kafka --network host \
--env KAFKA_HEAP_OPTS="-Xmx256M -Xms128M" \
--env KAFKA_ZOOKEEPER_CONNECT=127.0.0.1:2181 \
--env KAFKA_LISTENER_SECURITY_PROTOCOL_MAP=INSIDE:PLAINTEXT,OUTSIDE:PLAINTEXT \
--env KAFKA_LISTENERS=INSIDE://0.0.0.0:9092,OUTSIDE://0.0.0.0:9093 \
--env KAFKA_INTER_BROKER_LISTENER_NAME=INSIDE \
--env KAFKA_ADVERTISED_LISTENERS=INSIDE://{此处替换为私网IP}:9092,OUTSIDE://{此处替换为公网IP}:9093 \
wurstmeister/kafka
SpringBoot 集成Kafka
- 引入依赖包
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactId>
</dependency>
- 配置 Kafka 服务器
在application.properties中,加入如下配置:
#============== kafka ===================
# 指定kafka 代理地址,可以多个
spring.kafka.bootstrap-servers={服务器公网IP地址}:9093
#=============== 生产者配置=======================
spring.kafka.producer.retries=0
spring.kafka.producer.batch-size=16384
spring.kafka.producer.buffer-memory=33554432
# 配置消息体Key序列化器
spring.kafka.producer.key-serializer=org.apache.kafka.common.serialization.StringSerializer
# 配置消息体Value序列化器
spring.kafka.producer.value-serializer=org.apache.kafka.common.serialization.StringSerializer
#===============消费者配置=======================
# 指定默认消费者组id
spring.kafka.consumer.group-id=test-consumer-group
spring.kafka.consumer.auto-offset-reset=earliest
spring.kafka.consumer.enable-auto-commit=true
spring.kafka.consumer.auto-commit-interval=100
# 配置消息体Key反序列化器
spring.kafka.consumer.key-deserializer=org.apache.kafka.common.serialization.StringDeserializer
# 配置消息体Value反序列化器
spring.kafka.consumer.value-deserializer=org.apache.kafka.common.serialization.StringDeserializer
Kafka消息系统
发布/订阅消息系统
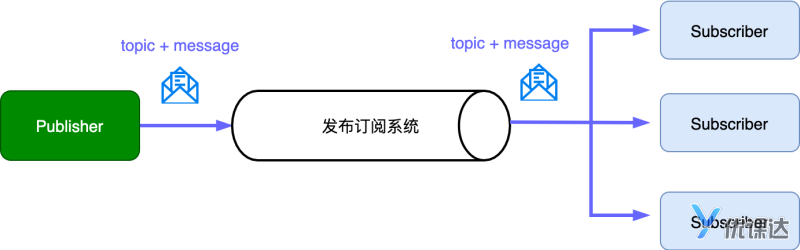
Kafka生产者 - 写入数据
发布,在Kafka中被称为生产者,也就是往Kafka中写入数据。
每个消息都有一个明确的主题Topic,用来筛选消息的订阅者。
在 Java 中,Kafka 消息用类ProducerRecord<K, V>表示。
为了网络传输,通常我们需要将内容进行序列化,同样Kafka也是如此,需要分别将Key, Value进行序列化。从application.properties中的配置属性可以看出key、value都是用的字符串序列化方式。所以消息应该是ProducerRecord<String, String>类型。
消息采用队列数据结构进行存储,先入先出,俗称消息队列。kafka为了支持消息的大量并发,实现了分区(Partition),每个分区都是一个队列,每个消息会按照一定的规则放置在某个分区里面。
默认情况下消息会被随机发送到主题内各个可用的分区上,并且通过算法保证分区消息量均衡。
如果消息体中有
Key,则会根据Key的哈希值找到某个固定分区,也就是如果Key相同则分区也将相同。

Kafka生产者 - SpringBoot中使用
@Controller
@RequestMapping("kafka")
public class KafkaSender {
// #1. 定义Kafka消息类型
@Autowired
private KafkaTemplate<String, String> kafkaTemplate;
//发送消息方法
@RequestMapping("/send")
@ResponseBody
public String send() {
// #2. 发送Kafka消息
kafkaTemplate.send("topic", "youkeda");//key为null的发送方法,第一个参数为主题Topic,第二个参数为消息内容value,
kafkaTemplate.send("topic","key", "youkeda");//key不为null的发送方法
return "success";
}
}
Kafka消费者 - 消费数据
Kafka 消息消费者类为KafkaConsumer
消费者组
就像多个生产者可以向相同的主题中写入消息一样,多个消费者也可以从同一个主题中读取消息,从而达到对消息进行分流。
一个消费者组里的消费者订阅同一个主题,每个消费者接受主题一部分分区的消息。
如果一个消费者组只有一个消费者,它将消费这个主题下所有分区的消息。
如果一个消费者组有多个消费者(但不超过分区数量),它将均衡分流所有分区的消息。
如果消费者数量和分区数量刚好相同,则每个消费者接收一个分区的消息。
如果消费者数量超过分区数量,那么超出部分的消费者将会闲置,不会接受任何消息。
一条消息只会被同组消费一次,也就是消息不会在同一个消费者组中重复消费,具有排他性。
多个消费者组订阅同一个主题,将分别消费这个主题的消息,也就是一个消息都会通知每个消费者组。
Kafka消费者 - SpringBoot中使用
@Component
public class KafkaReceiver {
// #1. 监听主题为topic的消息
@KafkaListener(topics = {"topic"})
public void listen(ConsumerRecord<?, ?> record) {
// #2. 如果消息存在
Optional<?> kafkaMessage = Optional.ofNullable(record.value());
if (kafkaMessage.isPresent()) {
// #3. 获取消息
Object message = kafkaMessage.get();
System.out.println("message =" + message);
}
}
}
注意代码中的注释:
-
#1需要利用注解的方式注册我们希望监听的 Kafka 消息主题,一旦有消息,将触发这个listen方法。 -
#2判断 kafka 消息是否存在Optional是 Java8 的工具类,主要用于解决空指针异常的问题。它提供很多有用的方法,这样我们就不用显式进行空值检测。这里主要用到三个常用的方法,以判断消息是否存在,如果存在则取出消息值。 -
#3获取 Kafka 消息中的消息体
实战订单通知
接入钉钉
- 引入 Maven 依赖
<dependency>
<groupId>com.aliyun</groupId>
<artifactId>alibaba-dingtalk-service-sdk</artifactId>
<version>1.0.1</version>
</dependency>
- 简单发送消息代码
@RequestMapping("/text")
@ResponseBody
public String sendText(){
// #0. 配置钉钉客户端,dingdingUrl即根据刚才拷贝的Webhook
DingTalkClient client = new DefaultDingTalkClient(this.dingdingUrl);
// #1. request表示整个消息请求
OapiRobotSendRequest request = new OapiRobotSendRequest();
// #2. 请求设置消息类别
request.setMsgtype("text");
// #3. 设置消息内容
OapiRobotSendRequest.Text text = new OapiRobotSendRequest.Text();
text.setContent("得物来新订单了");
request.setText(text);
// #4. 设置钉钉@功能
OapiRobotSendRequest.At at = new OapiRobotSendRequest.At();
at.setIsAtAll(true);
request.setAt(at);
try {
// #5. 发送消息请求
client.execute(request);
} catch (ApiException e) {
e.printStackTrace();
}
return "success";
}
构建通知应用
通知模型

通知服务设计

对接通知平台的接口称为NotifyHelper,这个接口有一个发送通知的方法sendNotify。
平台通知的Helper类需要实现NotifyHelper接口
监听器NotifyConsumer负责接收 Kafka 消息,利用它完成对Helper的调用。
流式处理
数据流
数据流也被称为事件流
数据流的特点
- 无穷的,或者说无边界的
数据就像河流一样源源不断地无限增长。
- 无处不在的
网站上发生的一切,都是数据流。
- 有序的
数据的到来总有个先后顺序。
- 不可变的
数据一旦产生,就不能被改变。
- 可重播
既然数据是无法改变的,在不改变数据的情况下,结果肯定是固定的,也就是如果将数据重新跑 N 次,结果总 是相同的。
流式处理
流式处理是指实时的处理一个或多个事件流
处理范式
- 请求与响应
特点:低延迟
- 批处理
特点:高延迟,高吞吐量
- 流式处理
特点:低延迟,高吞吐,持续性
时间
大多数流式处理应用都是基于时间窗口而进行的。
时间分为如下三种:
1. 事件时间
指事件或者数据产生的时间,也就是 Kafka 消息的时间
2. 处理时间
指事件或者数据被流应用处理的时间
3. 摄入时间
被处理以后的时间保存到 Kafka 主题的时间。
实战学习情况统计
流操作语法
1. 添加依赖
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-streams</artifactId>
</dependency>
2. 配置
# 指定应用名称
spring.kafka.streams.application-id=study-data-consumer
# 消息 key 的反序列化方式
spring.kafka.streams.properties.default.key.serde=org.apache.kafka.common.serialization.Serdes$StringSerde
# 消息 value 的反序列化方式
spring.kafka.streams.properties.default.value.serde=org.apache.kafka.common.serialization.Serdes$StringSerde
# 设置消息时间戳提取器
spring.kafka.streams.properties.default.timestamp.extractor=org.apache.kafka.streams.processor.WallclockTimestampExtractor
3. 创建流
使用 @EnableKafkaStreams 注解装配
@Configuration
@EnableKafkaStreams
public class KafkaStreamsConfiguration {
@Bean
public KStream<String, String> kStream(StreamsBuilder streamsBuilder) {
KStream<String, String> stream = streamsBuilder.stream("studyData");
... ...
return stream;
}
}
@EnableKafkaStreams 注解表示开启 Kafka 流。
系统会自动调用标注为 @Bean 的 kStream() 方法,传入 StreamsBuilder 实例对象参数。
streamsBuilder.stream() 完成流的创建,此方法参数是与发送端约定好的消息主题 studyData
流的常用操作:流映射
所谓流映射就是可以把对象进行转换,比如系统把接收到的消息反序列化为对象,我们可以在 map() 方法里转换为对象,方便下一步处理
stream.map((key, value) -> {
Student s = JSON.parseObject(value, Student.class);
return new KeyValue<>(key, s);
})
key 和 value 是消息发送者发送的,如果没有发送 key,则 key 值为 null。
map() 方法需要返回键值对 KeyValue 对象。
KeyValue 类是 Kafka 框架提供的类,专门用于封装流的 key-value pair 。
流的常用操作:流过滤
filter((key, value) -> {
return <条件语句>
})
filter() 方法参数是一个 Lambda 表达式,箭头后面是条件语句,判断数据需要 符合 的条件。
流的常用操作:流迭代
foreach((key, value) -> {
})
foreach() 方法用于遍历流中所有元素,是流的最终操作,意味着流的终结,不能再继续运算了。
流的分布式处理
如果一个大任务步骤较多,而正好有几台服务器可以执行任务,这时我们可以考虑利用这些服务器进行流的分布式处理。
大任务可以拆解成若干个独立的小任务,每个小任务之间不要有关联,特别不能有前后顺序的要求。
消息分发
stream2.to("studyDateCount", Produced.with(Serdes.String(), new JsonSerde<>()));
to() 方法用于将流中的对象作为新的 Kafka 消息发送出去:
-
第一个参数是指定新的 topic 名称。
-
第二个参数是指定 Key 和 Value 的序列化工具。
Produced.with()是比较方便的固定用法:- 基于约定,key 是简单的字符串,用
Serdes.String()作为工具 - 基于约定,value 是 JSON 格式的字符串,用
new JsonSerde<>()实例作为工具,系统自动把流中对象转化成 JSON 字符串发送。
kafkaTemplate.send() 发送消息,需要把对象转换为 JSON 字符串才能发送。
- 基于约定,key 是简单的字符串,用
to() 方法也是流的最终操作,后面不能再继续其它运算了。
我们可以使用前面的非最终操作返回的 KStream 对象,多次调用 to() 方法,发送多个子主题消息,每个主题消息由对应的子任务消费者完成具体的运算。
KStream<String, Student> stream2 = stream.map((key, value) -> {
... ...
}).filter((key, value) -> {
... ...
});
// 学习天数
stream2.to("studyDateCount", Produced.with(Serdes.String(), new JsonSerde<>()));
// 学习总时长
stream2.to("studyDuration", Produced.with(Serdes.String(), new JsonSerde<>()));
// 学习节数
stream2.to("studySections", Produced.with(Serdes.String(), new JsonSerde<>()));
// 代码行数
stream2.to("studyCodeRows", Produced.with(Serdes.String(), new JsonSerde<>()));
实战销售额分析
小知识点
Date转LocalDate
Date date = order.getGmtCreated();
LocalDate localDate = date.toInstant().atZone(ZoneId.systemDefault()).toLocalDate();
获取前一天的LocalDate
LocalDate localDate = LocalDate.now(); //获取今天的日期
LocalDate yesterday = localDate.plusDays(-1); //前一天日期是今天减1