
准备
MySQL主从复制
主从复制(也称 AB 复制)允许将来自一个MySQL数据库服务器(主服务器)的数据复制到一个或多个MySQL数据库服务器(从服务器)。
复制是异步的
具体配置
**1.Master节点配置/etc/my.cnf **(master节点执行)
## 同一局域网内注意要唯一
server-id=100
## 开启二进制日志功能,可以随便取(关键)
log-bin=mysql-bin
## 复制过滤:不需要备份的数据库,不输出(mysql库一般不同步)
binlog-ignore-db=mysql
## 为每个session 分配的内存,在事务过程中用来存储二进制日志的缓存
binlog_cache_size=1M
## 主从复制的格式(mixed,statement,row,默认格式是statement)
binlog_format=mixed
2.Slave节点配置/etc/my.cnf(slave节点执行)
## 设置server_id,注意要唯一
server-id=102
## 开启二进制日志功能,以备Slave作为其它Slave的Master时使用
log-bin=mysql-slave-bin
## relay_log配置中继日志
relay_log=edu-mysql-relay-bin
##复制过滤:不需要备份的数据库,不输出(mysql库一般不同步)
binlog-ignore-db=mysql
## 如果需要同步函数或者存储过程
log_bin_trust_function_creators=true
## 为每个session 分配的内存,在事务过程中用来存储二进制日志的缓存
binlog_cache_size=1M
## 主从复制的格式(mixed,statement,row,默认格式是statement)
binlog_format=mixed
## 跳过主从复制中遇到的所有错误或指定类型的错误,避免slave端复制中断。
## 如:1062错误是指一些主键重复,1032错误是因为主从数据库数据不一致
slave_skip_errors=1062
3.在master服务器授权slave服务器可以同步权限(master节点执行)
执行下面的mysql命令
# 授予slave服务器可以同步master服务
grant replication slave, replication client on *.* to 'root'@'slave服务器的ip' identified by 'slave服务器的密码';
flush privileges;
4.查询master服务的binlog文件名和位置(master节点执行)
show master status;

5.slave进行关联master节点(slave节点执行)
change master to master_host='master服务器ip', master_user='root', master_password='master密码', master_port=3306, master_log_file='mysql-bin.000002',master_log_pos=2079;
master_log_file 和 master_log_pos 都是通过 master服务器通过show master status获得。
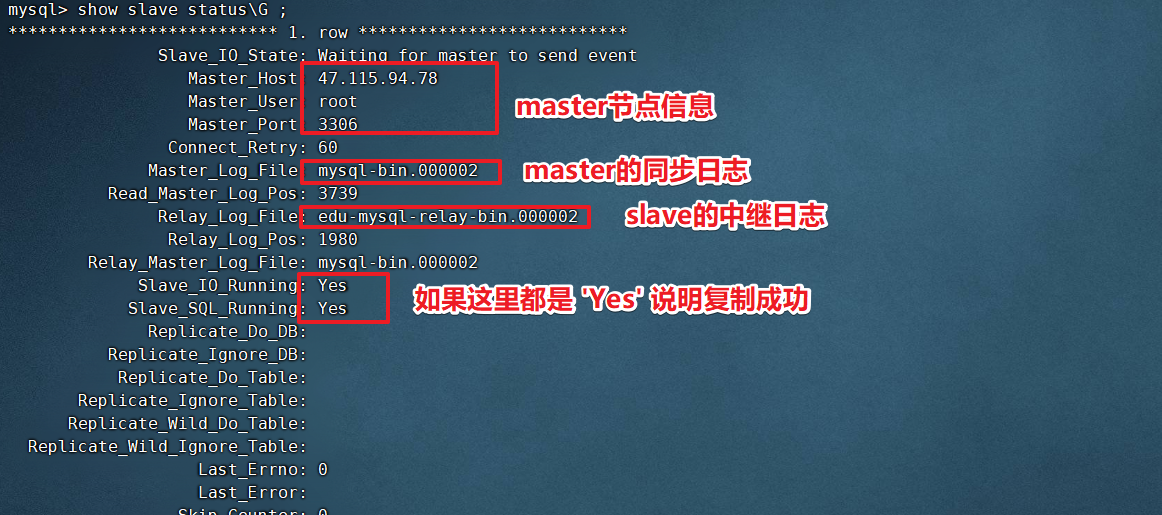
6.在slave节点上查看主从同步状态(slave节点执行)
启动主从复制
start slave;
查看主从同步状态
show slave status\G;
其他命令(slave节点执行)
# 停止复制
stop slave;
Sharding-JDBC
配置及读写分离
依赖
<!--依赖sharding-->
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>sharding-jdbc-spring-boot-starter</artifactId>
<version>4.0.0-RC1</version>
</dependency>
<!--依赖数据源druid-->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid-spring-boot-starter</artifactId>
<version>1.1.23</version>
</dependency>
定义配置application.properties
# 显示sql解析
spring.shardingsphere.props.sql.show=true
# 给每个数据源取别名
spring.shardingsphere.datasource.names=ds0,ds1
# 给主库ds0配置数据库连接信息
spring.shardingsphere.datasource.ds0.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.ds0.driver-class-name=com.mysql.cj.jdbc.Driver
spring.shardingsphere.datasource.ds0.url=jdbc:mysql://sh-cynosdbmysql-grp-knpl8owi.sql.tencentcdb.com:21104/springboot_demo?serverTimezone=GMT%2B8
spring.shardingsphere.datasource.ds0.username=root
spring.shardingsphere.datasource.ds0.password=ZABzueZ3
# 此处省略从库ds1的配置,同上 #
# 配置默认数据源ds0,默认数据源,主要用于写,注意一定要配置读写分离,如果不配置,那么就会把两个节点都当做从slave节点,新增,修改和删除会出错。
spring.shardingsphere.sharding.default-data-source-name=ds0
# 配置数据源的读写分离
spring.shardingsphere.masterslave.name=# 配置主从名称,可以任意取名字
spring.shardingsphere.masterslave.master-data-source-name=ds0
# 多个从库用逗号隔开
spring.shardingsphere.masterslave.slave-data-source-names=ds1
# 配置slave节点的负载均衡均衡策略,采用轮询机制
spring.shardingsphere.masterslave.load-balance-algorithm-type=round_robin
分库分表
一、inline 行表达分片策略
# account为逻辑表名
# 数据节点
spring.shardingsphere.sharding.tables.account.actual-data-nodes=ds$->{0..1}.account_$->{0..9}
# 拆分表策略
spring.shardingsphere.sharding.tables.account.table-strategy.inline.sharding-column=account # 分片键
spring.shardingsphere.sharding.tables.account.table-strategy.inline.algorithm-expression=account_$->{account % 10} # 分片算法表达式
# 拆分库策略为database-strategy
分片键只能为数字类型,字符类型不行
二、标准分片策略
spring.shardingsphere.sharding.tables.account.actual-data-nodes=ds$->{0..1}.account_$->{0..9}
spring.shardingsphere.sharding.tables.account.table-strategy.standard.sharding-column=account
# 自定义分片策略,指定类路径
spring.shardingsphere.sharding.tables.account.table-strategy.standard.precise-algorithm-class-name=com.geekgame.demo.config.TablePreciseShardingAlgorithm
自定义分片策略类
public class TablePreciseShardingAlgorithm implements PreciseShardingAlgorithm<String> {
@Override
public String doSharding(Collection<String> collection, PreciseShardingValue<String> preciseShardingValue) {
return "account_"+(Integer.parseInt(preciseShardingValue.getValue())%10);
}
}
绑定表
那些分片规则一致的主表和子表。比如:t_order 订单表和 t_order_item 订单服务项目表,都是按 order_id 字段分片,因此两张表互为绑定表关系。
通常在我们的业务中都会使用 t_order 和 t_order_item 等表进行多表联合查询,但由于分库分表以后这些表被拆分成N多个子表。如果不配置绑定表关系,会出现笛卡尔积关联查询,降低联合查询效率。
# 多个表用逗号分开
spring.shardingsphere.sharding.binding-tables=t_order,t_order_item
要保证绑定表之间的分片键要完全相同。
分布式主键
spring.shardingsphere.sharding.tables.逻辑表名.key-generator.column=# 主键
spring.shardingsphere.sharding.tables.逻辑表名.key-generator.type=SNOWFLAKE
主键列不能自增长。数据类型是:bigint(20)
分布式事务
依赖
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>sharding-jdbc-spring-boot-starter</artifactId>
<version>${sharding-sphere.version}</version>
</dependency>
<!-- 使用XA事务时,需要引入此模块 -->
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>sharding-transaction-xa-core</artifactId>
<version>${sharding-sphere.version}</version>
</dependency>
<!-- 使用BASE事务时,需要引入此模块 -->
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>sharding-transaction-base-seata-at</artifactId>
<version>${sharding-sphere.version}</version>
</dependency>
用法
在要执行的事务方法上加上注解
本地事务:支持非跨库事务
@ShardingTransactionType(TransactionType.LOCAL)
@Transactional(rollbackFor = Exception.class)
两阶段事务-XA:支持跨库事务
@ShardingTransactionType(TransactionType.XA)
@Transactional(rollbackFor = Exception.class)
远程调用进行事务回滚需要结合Seata
注意事项
使用druid时换成下面的依赖
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid</artifactId>
<version>1.1.23</version>
</dependency>